CPDoS: Cache Poisoned Denial of Service
⚠️ Le blog a été déplacé vers le site Patrowl, vous serez redirigé automatiquement dans 3 secondes, sinon cliquez sur ce lien : https://patrowl.io/cpdos-cache-poisoned-denial-of-service/
👍 Vous y retrouverez toutes les nouvelles publications
Voici une rapide explication concernant l’attaque de déni de servie CPDoS ou Cache Poisoned Denial of Service. L’attaque est détaillée ici : https://cpdos.org/ (et sur archive.orgau cas le site disparaitrait).
Le cache c’est la vie
Que ce soit dans vos microprocesseurs, vos logiciels et la plupart de vos sites web : le cache est au cœur des performances.
Lorsque vous (enfin plutôt un logiciel) va demander au microprocesseur de traiter des données de la mémoire RAM, elles sont « cachées » dans différentes niveaux de cache, les plus rapides étant les plus cher. S’il y’a besoin d’accéder à nouveau à ces données, magie, elles sont dans le cache, inutile d’aller les chercher dans la mémoire principale (la RAM), trop lente (et encore moins sur le disque dur).
Il en est de même pour un site web. Vous faites une requêtes qui va être traitée par une application, lente, qui va faire des requêtes à une base de données… et vous renvoi le contenu. Beaucoup de sites mettent des caches devant les applications (c’est le métier de base des CDN / Content Delivery Network) et, suivant les réglages, si une requête similaire a été faite récemment, c’est le contenu caché qui vous est renvoyé sans solliciter la véritable application/site web.
CPDoS
CPDoS utilise plusieurs variantes d’une même attaque : faire une requête à travers un service de cache qui sera transmise à l’application/site web mais génèrera une erreur, erreur qui sera cachée, rendant l’application/site virtuellement injoignable pour les autres clients (le temps que le cache périme). Il suffit alors de répéter l’attaque.
Le schéma du site est suffisamment clair pour ne pas avoir à le redessiner 😉 :
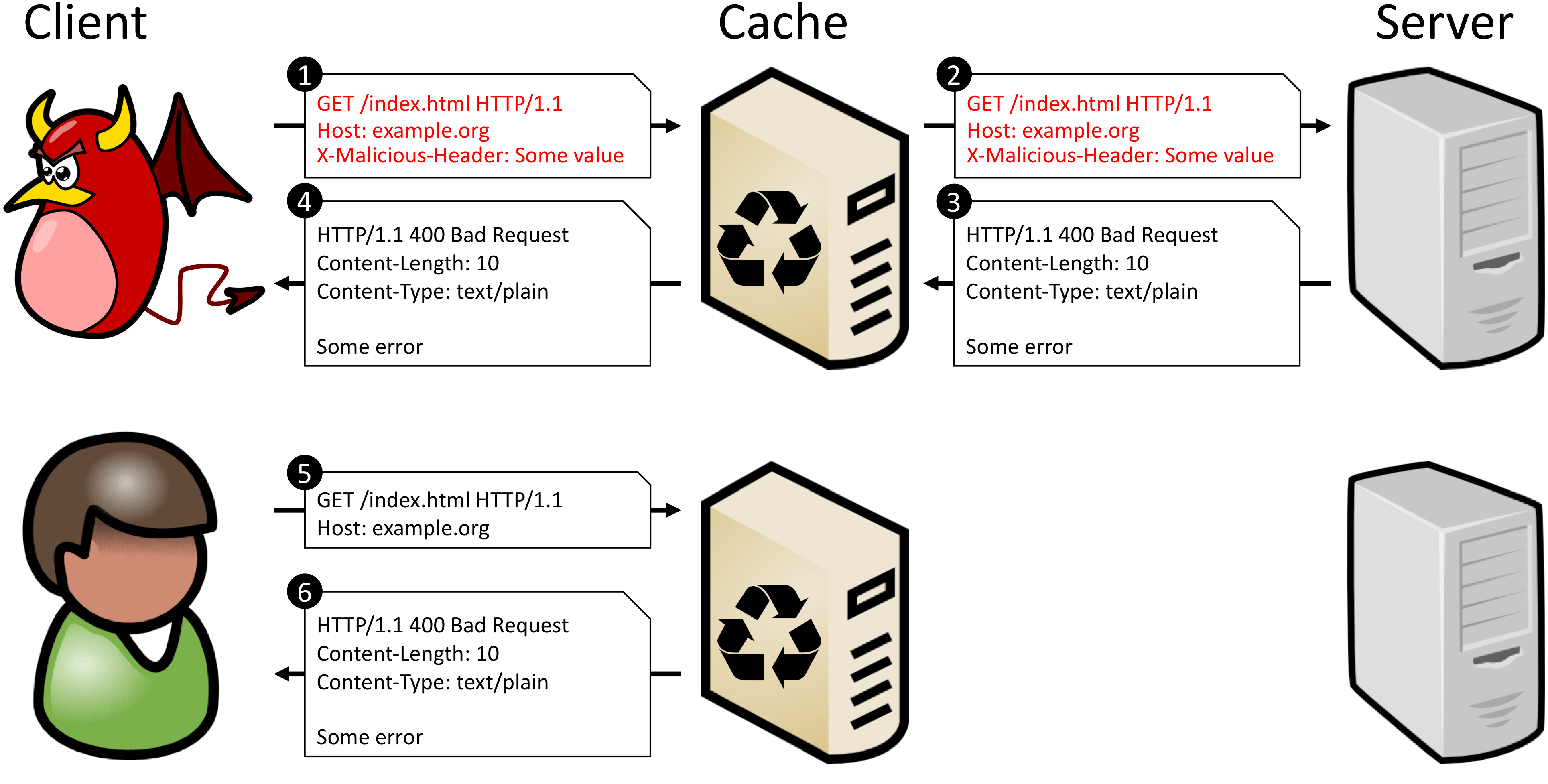
L’article présente 3 variantes de cette attaque :
- HTTP Header Oversize (HHO), basée sur l’idée que la taille des entête HTTP, bien que théoriquement illimitée, dispose d’une limite chez chaque éditeur. Si le cache accepte une taille d’entête supérieure à ce qu’accepte le serveur web, alors il suffit d’envoyer un gros entête qui sera accepté par le cache mais génèrera une erreur sur le serveur. Par exemple, le CDN Amazon Cloudfront accepte 20 480 octets, alors qu’Apache HTTPD accepte 8192 octets ;
- HTTP Meta Character (HMC), basée sur le fait de mettre dans les entêtes des métacaractères acceptés par le cache mais générant une erreur sur le serveur (comme un passage à la ligne, un retour chariot, un saut de page…) ;
- HTTP Method Override (HMO), basée sur un cas très particulier d’application utilisant les entêtes HTTP pour spécifier les méthodes d’appel (GET, POST, DELETE…), non traité par les caches mais générant une erreur sur le serveur, comme une soumission (« X-HTTP-Method-Override: POST ») sur une page ne l’acceptant pas.
Vous l’aurez compris, l’idée est d’avoir une technique générant une erreur sur le serveur mais sans comportement spécifique sur le serveur de cache, à l’aller.
L’article cité au début présente un tableau des technologies vulnérables et CloudFront est (était) quasiment vulnérable à tout 😉.
Contre-mesures
Une bonne protection face à ces attaques est de juste exclure les pages d’erreur du cache, mais avec le risque qu’elles servent alors à faire du déni de service classique.
Sinon, certains WAF peuvent protéger contre ces attaques avec leur protection contre les non-conformités protocolaires et leurs seuils, s’ils sont placés devant le cache.